

6 AI Principles That Stack. Miss One, and the Rest Fall Apart

This is the second article in the "AI Map for PMs" series. In the first one, we introduced the C³ framework (Concepts, Capabilities, Channels) and the five progression levels. Today we go deep on the first C: concepts.
According to McKinsey, 78% of organizations already use AI in at least one business function. But only 6% generate real, measurable impact1. 78% adopted. 6% understood. And the difference isn’t the tools. Those are the same for everyone.
Meta just redesigned their PM interviews for the first time in five years. The new focus: what they call “AI Product Sense”, the ability to understand what models can and can’t do, map failure modes, and define minimum viable quality2. They’re not asking you to train a model. They’re asking you to understand how it works well enough to make good decisions.
That boils down to six concepts. And they have a logic that isn’t obvious: the first five stack. Each layer needs the one below to work well. The sixth is a guardrail that applies across all of them.
The 5 layers + 1 guardrail
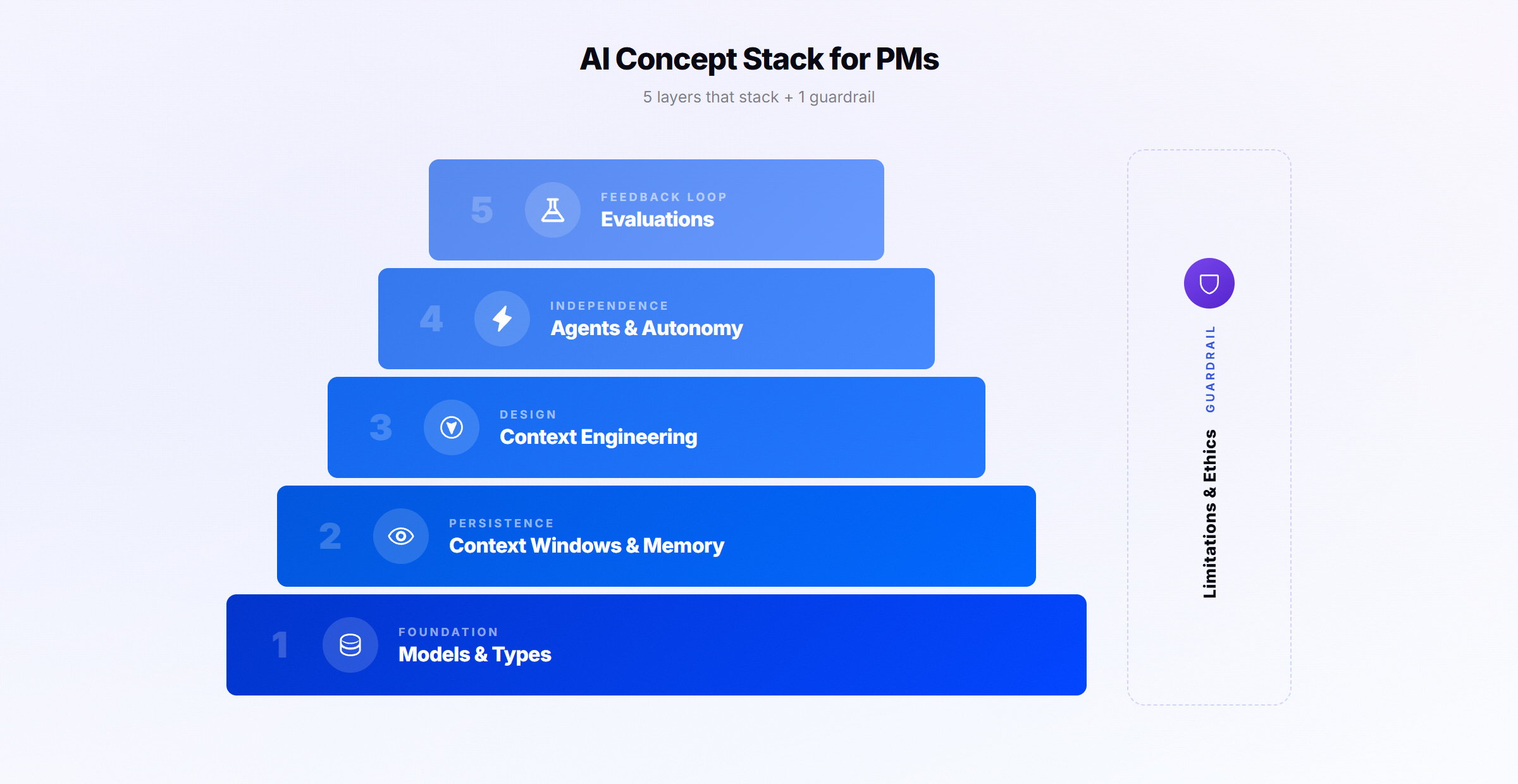
Layer 1: Models and Types (the foundation)
“AI” is not one thing. It’s families of models with different capabilities: efficient general-purpose models for everyday tasks (Claude Sonnet, GPT-5), deep reasoning models for complex analysis (Opus, Gemini Pro), fast and cheap models for volume (Haiku, Gemini Fast). Plus specialized ones for image (nano banana), video (Sora), or voice (ElevenLabs).
The skill is knowing when to use which. An example: you have 200 pieces of feedback to synthesize one by one. You could run the most powerful model on all 200 (slow and expensive). Or you could use a fast model to classify by theme, and the powerful one only for pattern analysis. Same result, fraction of the cost and time.
According to LangChain, over 75% of teams using AI in production already work with multiple models3. The PM who uses one model for everything is the exception, not the rule.
Layer 2: Context Windows and Memory (persistence)
Models can retain information, but there are levels. The conversation is volatile: close the chat, everything’s gone. Persistent context (Claude Projects, Custom GPTs, Gemini Gems) keeps instructions and documents across conversations. Persistent memory (Claude Memory, ChatGPT Memory) remembers your preferences without you configuring anything.
Most PMs work at level 1, starting from scratch every time. It’s like talking to a new stranger every day instead of a colleague who already knows your situation. The level of memory you use determines whether results are generic or specific to your context.
Layer 3: Context Engineering (design)
Context windows and memory are the AI’s ability to see and retain information. Context engineering is your ability to give it the right information.
Prompt engineering is writing a good prompt. Context engineering is designing the entire environment: reference docs, tools, system instructions, memory. Andrej Karpathy put it this way: “The LLM is like the CPU, and its context window is the RAM. Your job is to load that memory with exactly the right data for the task.”
To make it concrete: ask a generic chat “help me prioritize these 8 features,” and you get a generic matrix with made-up criteria. Ask the same thing to a project that has your north star metric, last quarter’s retention data, and the context that your team is 4 devs running 2-week sprints, and it says: “Of these 8, only 3 directly impact your north star. And of those 3, feature B has the best impact/effort ratio given your team size.” Same model, same question. The difference is the context.
Here’s a key data point: a 2025 study showed that model accuracy drops 24% when relevant information is buried in the middle of a lot of irrelevant context4. It’s not just how much context you give it. It’s how well-organized that context is.
Layer 4: Agents and Autonomy (independence)
The progression goes from prompt-response (you ask, it answers) to copilot (assists in real time) to agent (executes multi-step tasks on its own) to autonomous systems (run complete workflows with minimal oversight).
Each level enables things that the previous one can’t. But errors compound: if each step has 95% accuracy, after 20 steps your probability of success drops to 36%. Knowing which level you’re at, and especially how much oversight each level needs, is critical.
Layer 5: Evaluations (the feedback loop)
More autonomy means the AI makes more decisions without you. How do you know what it decides is any good?
46% of organizations have no formal process to validate AI quality. The dominant practice is the “vibe check”: try a few prompts, see if it “feels right,” and give the OK. But AI is probabilistic. The same prompt can give different results every time.
An evaluation can be as simple as a rubric: “a good summary has at most 5 insights, each with quantitative evidence and a product implication.” With that, you can already compare two prompts and see which one performs better. And when you need to scale, you can use another model as a judge (LLM-as-judge), which shows 80% agreement with human evaluators5.
But the most powerful thing about evaluations is that they tell you where the problem is in the previous layers. If the output hallucinates data, it’s probably a context problem (missing reference material). If the analysis is shallow, maybe you need a model with deeper reasoning capability. If results vary wildly between agent runs, maybe you gave it too much autonomy, and it needs more checkpoints. Evaluations don’t just measure quality. They diagnose which layer of the stack you need to improve.
6th Principle - Guardrails: Limitations and Ethics
This one doesn’t stack. It wraps around all of them. Three things to keep in mind:
Bias. Models were trained on data that’s predominantly in English, from developed markets, and with mainstream perspectives. If your product serves a specific niche (fintech for informal workers, healthcare in rural areas, education in emerging markets), the “best practices” the model assumes may not apply to your context. It’s not that the model is broken. It’s that its worldview has blind spots.
Regulation. If your product operates in Europe and uses AI for decisions that affect people (employment, credit, education), the EU AI Act, going into effect in August 2026, will require technical documentation, impact assessments, and human oversight. In the US, there’s no federal law, but states like Colorado and Illinois already have their own regulations. There are limits on what data you can send to an external API, and it’s worth knowing them before connecting AI to your systems.
Vendor lock-in. If your entire process depends on one model from one company, a price change, policy shift, or API outage can leave you at zero. Context engineering helps here: if your context is well documented (instructions, rubrics, reference docs), switching providers is much easier than if everything lives in the head of whoever wrote the prompts.
The cascade effect
Watch how they stack: pick the right model, but don’t give it memory, and you start from zero every time. Give it memory, but don’t design the context, and the results are inconsistent. Design the context, but don’t give it autonomy, and you’re doing everything manually. Each layer adds value to the next.
And when you measure and something fails, evaluations point to the exact layer where the problem is. The stack becomes a system that feeds back into itself.
Diagnostic: Which layer are you stuck at?
Your AI outputs are generic? Layer 2-3 problem. You’re probably missing persistent context, or the context isn’t well organized.
Results are good sometimes and mediocre other times? Layer 3 problem. The context isn’t consistent, or it’s missing key information.
You can’t scale your use of AI? Layer 4 problem. You’re doing everything manually when you could delegate to agents.
You don’t know if your AI works well? Layer 5 problem. You don’t have evaluation criteria defined.
Everything works, but the costs don’t add up? Layer 1 problem. You’re using the wrong model for the task.
Start with the layer where you’re stuck. You don’t need to master all six to get started. But understanding they exist lets you see what you’re leaving on the table.
Want to go deeper on these concepts? In the Product Direction community, we work on these topics every week with real cases. Learn more about the community
McKinsey State of AI 2025, 1,993 respondents.
Lenny Rachitsky, "How Meta is rethinking the PM role for AI" (February 2026).
LangChain, State of Agent Engineering 2025.
Liu et al. (2025), "Lost in the Middle: How Language Models Use Long Contexts."
Zheng et al. (2023), replicated in Judge's Verdict Benchmark (2025).